Why Agentic Wins (and Why It Sometimes Doesn't)
This is a breakdown of a real LLM-powered system I built, broke, and rebuilt. The differences in my first and second iteration changed how I approach programming AI systems today and it explains why “agentic AI” is suddenly everywhere.
If you’re building LLM-based tools and running into edge cases or poor AI decision making, this post could be the key to addressing that. If you’re already building agentic AI systems, some of this might feel obvious. But I think going back to why we do something in the first place can be useful. We’ll also try to understand where and why my initial design excels.
In this post, I’ll walk you through the process that led to my redesign, highlighting its advantages and comparing it to the original procedural approach. We’ll then generalize these insights and provide a beginner’s guide to the approach I use when designing automated AI systems.
Table of Contents
- The Problem That Started It
- Setting The Scene
- The Breaking Point
- The Realization
- The Agentic Redesign
- Comparative Analysis: A Stress Test
- Tradeoffs and When to Use Each Approach
- The In Between: Is It Valid?
- Getting Specific: Let’s Talk Implementation
- Conclusion
- Footnote
The Problem That Started It
After shipping my AI-powered automated school announcement board, I had a problem: it was unmaintainable, undebuggable, and rather stupid. The Python script was dense with error handling, nested conditionals, and validation functions. This was an early project integrating generative AI into applications.
What I learned from this project changed my fundamental approach to designing any LLM-powered system.
I rebuilt it with a different design blueprint. Everything changed. Better functionality while going from ~1,750 words to ~550 words of core system prompting. 10x more flexible at handling edge cases. I no longer got questionable results from my program on a Tuesday scheduled cron job.
In this article, I’ll share everything I learned. It’s about the fundamental difference between code with AI vs. AI with code.
Setting The Scene
I had developed a centralized digital school notices and upcoming events board (visible through a website) for my school. My next piece in this system was automated processing: take school announcements from Google Classroom (my school’s native platform where teachers post announcements and assignments) and post them to our digital notice board. Straight forward? I wished.
At first, I sketched out what seemed like a sensible high-level plan with basic procedural steps:
- Poll Google Classroom for new announcements every 15 minutes (cron job)
- Decide whether each new announcement should be an event or notice on the board (LLM prompt)
- Summarize, shorten and formalize the announcements (another LLM task)
- Pick appropriate dates for showing/removing the announcement (with an LLM)
- Post to my announcement board
I thought: “Perfect! I’ll use an LLM for all these semantic, iffy evaluation tasks. I’ll just need some prompting and output validation.”
Here’s what that initial process looked like in code:
function process_announcements():
new_announcements = check_for_new_announcements()
for each announcement in new_announcements:
# Step 1: Classify announcement
post_type = LLM("Is this an event or a notice?", announcement.text)
# Step 2: Check for duplicates
existing_items = get_existing_posts(post_type)
is_duplicate = LLM("Is this announcement a duplicate?",
new=announcement.text, existing=existing_items)
if is_duplicate:
mark_as_processed(announcement.id)
continue
# Step 3: Extract and format data
post_data = LLM("Extract title, description, dates, target years",
announcement.text)
if missing_required_fields(post_data):
log_error("Missing fields in announcement", announcement.id)
continue
# Step 4: Post to backend
if post_type == "notice":
post_to_api("/api/notices", post_data)
else:
post_to_api("/api/events", post_data)
mark_as_processed(announcement.id)
Notice the pattern: each step is isolated, makes an LLM call, validates the output, and passes data to the next step. It seemed logical. Clean separation of concerns, easy to debug each step. Classic software engineering principles.
The Breaking Point
The initial approach worked, until it didn’t. I learned that Google Classroom announcements are a mess of edge cases waiting to break everything. Soon my 5-step pipeline had to handle announcements that:
- Were corrections to previous posts: “The assembly is at 2pm, not 1:30!”
- Weren’t relevant: “John and Sarah, please come collect your textbooks”
- Contained multiple individual notices: “Here’s some notices for the week: …”
- Had vital context in attached images: “Check the attached image for this week’s schedule”
- Were both an event AND a notice
- Were duplicates posted across classes at once
- Should be merged with existing board items, not posted separately
And more!
My instinct as a systems-oriented programmer was to treat each exception as a branch in the logic. So I started creating functions to address each edge case:
def check_if_merging_announcements_are_suitable(announcement, existing_notices):
"""Prompt the LLM, asking it to assess if this notice should be merged
with an existing one based on the current notice board"""
prompt = f"""...""" # Another verbose, context-stuffing prompt
response = call_llm(prompt)
# Sanitize and extract the final judgement
# Convert from string to data type
# Error handling
# ...
Very quickly, the once-straightforward system transformed into:
└── For each recent announcement:
├── Check if already processed
├── If new/updated → Process announcement:
│ ├── Extract text and materials (files, links, videos)
│ ├── AI Relevance Check: Is this suitable for notice board?
│ │ └── If not suitable → Skip and mark as processed
│ ├── AI Classification: Is this an "event" or "notice"?
│ ├── Duplicate Detection:
│ │ ├── Query existing notices/events from backend
│ │ ├── AI comparison to find duplicates
│ │ └── If duplicate → Update targets or skip
│ ├── Content Processing:
│ │ ├── Determine dates to show notice / event
│ │ ├── AI content condensation, formatting and formalizing
│ │ └── Create structured JSON (title, description, dates)
│ └── Post to backend
└── Continue to next announcement
Though tedious, I tried to create a branch of logic for every random post, silly announcement, and mistake that could occur. By the end, my code became a mountainous heap of if statements and LLM task evaluation functions, bound by the rigid, stepwise process I outlined to solve the once-seemingly straightforward problem.
Yet even still, I’d get the occasional 2pm email from Render.com saying my service failed, and mornings where duplicate announcements had snuck through.
If I wanted something all-encompassing, dependable and sturdy, this wasn’t it.
The Realization
The solution slowly became clear when I began distancing myself from the problem: I was treating this like a programmer would, so I stepped back and thought about how a human would solve it. It made me realize I was writing logic in the wrong language.
I was still programming like the machine needed rigid instructions. Like I was writing code, not using reasoning. But LLMs don’t operate like CPUs. They don’t follow deterministic execution; their superpower is holistic reasoning, contextualization, and inference.
When I placed an LLM in the role of evaluating a single statement (e.g. ‘determine if this post is suitable for the board, yes or no?’), I was feeding it tunnel-visioned tasks as part of some bigger pipeline, while attempting to stuff enough context through verbose prompting so it could do a half-decent job.
To illustrate, here’s a prompt from one branch in that conditional tree:
You are an AI assistant tasked with determining the suitability of school
announcements for being put on the school notice board. Your role is to
evaluate whether the announcement is appropriate for inclusion on the school
notice board or if it is too specific and only relevant to a small group of
people. In general try to be lenient.
Use the following criteria to make your decision:
- Announcements meant for very small groups (e.g., a subset of a class,
maybe those who have missed deadlines) are not suitable for the school
notice board.
- You must exclude the announcement if it contains sensitive information,
like full names, passwords or other information that is meant to be private.
- Add everything that passes the first 2 rules.
Announcement Content: {description}
Respond with only "true" if the announcement is suitable for inclusion on the
school notice board, and only "false" if it is not. Do not provide any
explanation, reasoning, or additional text in your response.
The problem had nothing to do with the prompt quality; it was a textbook ideal prompt. Rather, the issue was task context. Explaining the background information (‘tasked with determining…’) was a workaround trying to compensate for the model’s blindness.
This approach brought a plethora of issues:
Fixing behavior was hell: You didn’t know what the AI was thinking to arrive at a decision (because really, it wasn’t thinking much). When a final action was unexpected, it was rarely clear which step was the culprit. That’s a problem with long dependency chains in general: every link must work perfectly; if one breaks or misbehaves, the whole system fails.
Each step lacked context: Only from a distance could we see why one choice didn’t make sense in the wider context. These AI tasks were tunnel-visioned badly. Thus, blind to the full task, they were unable to make reasonable choices.
Prompts became verbose and inefficient: Writing and tweaking prompts became a chore. Having higher OpenAI API bills each month wasn’t nice either.
Edge cases were inevitable: It would eventually encounter something the system wasn’t designed for, a branch in the code that didn’t exist.
The problem was that my solution was more code than LLM. Like an inefficient corporate middle-management system, we needed a smart guy to come in and single-handedly do the entire thing. From my first draft, the complexity wasn’t supposed to grow code-wise, it was supposed to grow prompt-wise. LLMs are closer to handling tasks like humans, so giving them a task the same way you’d give a human one was the smarter choice. I think I didn’t see this because I was too used to thinking like a ‘classical’ programmer.
The Agentic Redesign
After going back to the drawing board, I understood that breaking down the problem into 25 pieces wasn’t the method. The solution was blatantly simple (and scarily easy): describe the entire problem in a single LLM prompt and provide it with the tools that any human doing the same task would need (e.g. post to backend, check existing board, query classroom data). This is essentially the nucleus of agentic design: providing agency.
Leveraging tool calling and large context windows was key. High-agency models trained for tool use, like Anthropic’s Sonnet 4 (and now 4.5), were particularly impressive at this task.
I found it interesting how the second iteration wasn’t too dissimilar from the original draft solution. I still kept that branch-like conditional structure—not in the code but in the prompt. I described the entire decision-making procedure as a task to the agent.
Here’s what came out of that, the agentic AI system that worked:
START
├── Fetch Data
│ ├── Announcements + assignments from Classroom
│ └── Current state of board (notices + events)
│
├── Construct Agent Context
│ └── Compile prompt with environment, data, and operational rules
│
├── Agent Loop (≤ 8 iterations)
│ ├── Sonnet-4 receives full context and available tools
│ ├── Chooses tools, executes functions, reasoning is logged
│ ├── Receives updated state + conversation history
│ └── Re-evaluates until calling `finish_processing()` or max steps
│
├── Available Agent Tools:
│ ├── Information Gathering:
│ │ ├── get_announcements() → Latest classroom announcements
│ │ ├── get_assignments() → Upcoming assignments
│ │ ├── get_existing_notices() → Current notice board
│ │ └── get_existing_events() → Current events board
│ ├── Content Management:
│ │ ├── create_notice(title, desc, dates, targets)
│ │ ├── update_notice(id, title, desc, dates, targets)
│ │ ├── delete_notice(id)
│ │ ├── create_event(name, desc, date)
│ │ ├── update_event(id, name, desc, date)
│ │ └── delete_event(id)
│ └── Session Control:
│ └── finish_processing(message) → End with summary
│
└── Terminate
├── Agent ends session or times out
└── Return summary of actions taken
Delightfully, the code itself became far simpler because I could neatly separate API and tool functionality with the AI prompting, as opposed to having them mix throughout the code, like with the procedural design.
The paradigm shift is subtle but changes everything: put the logic and decision-making into the LLM, not the code. Treat the system like a human employee (but with steering and guardrails). This design enables the once-rigid procedural logic to become dynamic and reasoned—acting more as guidelines, not bolted-down rails.
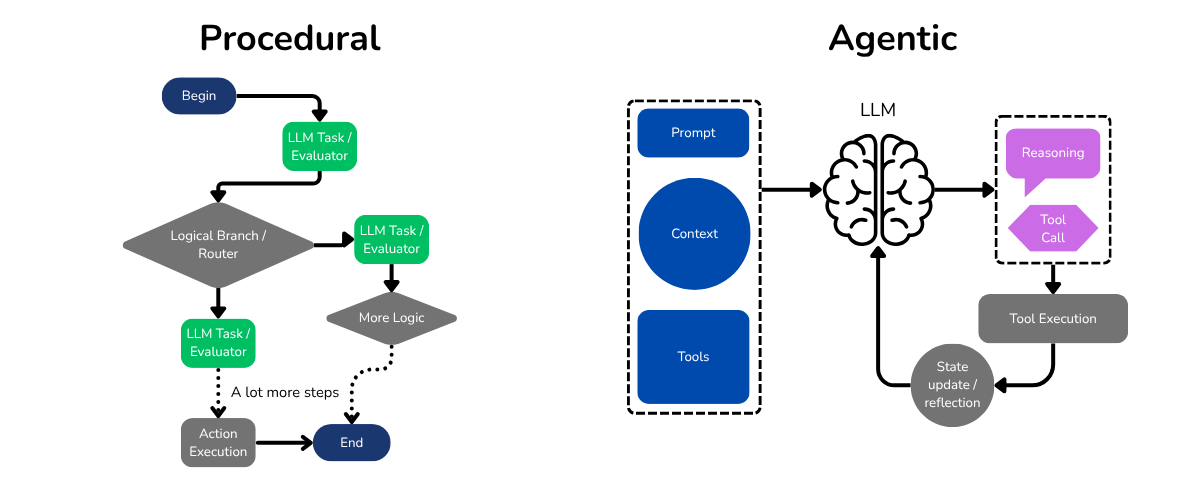 I made this illustration to show the general architecture of both types of systems, agentic and procedural.
I made this illustration to show the general architecture of both types of systems, agentic and procedural.
The Prompt
Good prompting was core to the success of this agent (and any other agent). Here’s the central system prompt I refined with lots of testing:
You are a digital school board assistant for XXX School's 'Tutor Board' app. Your primary responsibility is to create, update, and manage notices and events based on data from the school's Google Classroom system.
You have access to the following information:
1. Current date and time:
<current_date_time>{strftime('%Y-%m-%d %H:%M:%S')}</current_date_time>
2. Google Classroom data to process for today (announcements and assignments):
{classroom_data}
3. Current state of the Tutor Board for reference and context:
<current_board_state>{board_data}</current_board_state>
Your task is to process this information and make appropriate updates to the
Tutor Board. Follow these guidelines:
1. Analyze each item from the Google Classroom data:
a. Determine if it's relevant for the Tutor Board
b. Decide whether it should be a notice or an event
c. Create or update the notice/event accordingly
2. Notice vs Event:
- Notice: An announcement or information (e.g., new canteen rules)
- Event: A specific date and time activity (e.g., bake sale, assembly)
- Refer to the current board for good examples of how these are categorized
3. Clean up work:
- Consider if new information can be merged with existing events/notices
- If a notice is outdated or irrelevant, remove it from the board
- Delete notices/events that are no longer relevant or have expired
4. Manage duplicates:
- Remove or merge duplicate notices/events as needed
- Avoid unnecessary modifications to existing entries
5. Formatting requirements:
- Links: Use [URL title](URL) format
- Description: Keep under 1024 characters
- Title: Keep under 80 characters
- Remove sensitive information (full names, passwords, private details)
6. Dates:
- Infer start and end dates from context
- For notices, aim for shorter timeframes (rarely longer than 1 week)
7. Target year groups:
- Assign appropriate year groups based on context
- IB Notices: Years 12 and 13
- Key Stage 3: Years 7, 8, and 9
- Key Stage 4: Years 10 and 11
- Default: All year groups (7-13) if unclear
8. Tool usage:
- You have 8 'rounds' of tool calling. You must plan and finish within that budget
- Run tool calls concurrently when possible
- If a tool call fails, try once more before moving on
- Use finish_processing when all suitable changes are made
After processing, use finish_processing and provide a recap of actions taken.
Remember: you have autonomy to organize the Tutor Board. This includes merging
information, removing outdated content, or updating existing items based on new
information from Google classroom. Notice how events and notices are currently categorized and written on the board and maintain that consistency.
A pattern in prompt design I discovered from this is to tell the model to self reference its own previous outputs to understand conventions and expectations of the task. The agent then feeds into these existing implicit patterns on the board, which makes outputs less random and more consistent across different scenarios. Moreover, this leads to less unpredictable and incongruent behavior of the agent. A simple “refer to the current board for good examples” or “notice how events and notices are currently categorized” works. I considered the possibility of a slow drift in behavior over time if the prompting wasn’t tight enough, however I haven’t tested this rigorously. Now I try to implement this continuously self-referencing design pattern in my other systems.
Another important thing I found out was that guiding the reasoning with a procedure was detrimental to the quality of the output. Forcing the model to reason through each consideration one by one made it not glaze over anything, like leaking a password or not contextually adjusting the time of the student council meeting. Guidelines also reduce the agent going haywire with tool calls, thinking it needs to do more than it should. I’ve noticed models can act too high-agency sometimes and cause issues.
In Short,
Provide full context upfront: Current board state, new data, current time—everything a human would need
Guide, don’t constrain: Outline considerations and best practices, but let the agent reason
Give examples implicitly: By showing current board state, the agent learns the style and patterns
Set boundaries: Tool budgets, formatting limits, required checks (like removing passwords)
Encourage initiative (or the opposite, to your liking): “you have autonomy to organize” prevents the agent from being too passive
Comparative Analysis: A Stress Test
Let’s see how these two systems handle a complex, multi-faceted announcement, the kind that broke my procedural system regularly.
Starting board state (both systems):
*Notices:*
- Year 10 Community Service Hours Reminder
- Misc. notices to add real-life complexity
*Events:*
- Student Council Meeting (Tuesday, Jan 18th, 3:30 PM)
- Misc. events to add real-life complexity
Test announcement:
Hey all, 3 announcements for today:
MATH COMPETITION: Inter-school Mathematics Olympiad on Saturday, Feb 5th.
Year 9-11 students who scored above 85% in last term's exam are eligible.
Sign up by Jan 28th.
REMINDER: All Year 10 students must complete their community service hours documentation by the end of this month. Forms available in Student Services. Login with password "school5" for the form.
NEW CLUB: Environmental Action Group starting next week. First meeting Tuesday
Jan 18th, 3:30 PM in Science Lab 2. Open to all years. The Student Council meeting will be moved to after the meeting.
This announcement contains:
- 3 separate items to process in one Google classroom post
- A password that should be removed
- A duplicate topic (Year 10 community service)
- A scheduling conflict requiring an update to existing events
Procedural System Results
Performance: 5.49s, 760 tokens
Decision 1: Relevance Check
├─ Input: Full text
└─ Output: Relevant (PASS)
Decision 2: Event vs Notice
├─ Input: Full text (all 3 announcements)
└─ Output: "event"
Decision 3: Duplicate Check
├─ Input: Full text vs existing events
├─ Output: "2" (Student Council Meeting)
└─ Verdict: ❌ FALSE POSITIVE (confused update with duplicate)
FINAL: Update existing event
└─ Verdict: ❌ INCORRECT (lost 2/3 of announcements)
The procedural system failed catastrophically. It couldn’t separate the three announcements, classified all of them as a single “event”, then got confused by the mention of the Student Council meeting and thought the entire thing was a duplicate.
Agentic System Results
Performance: 6.79s, 2,874 tokens
Iteration 1: Context Gathering
├─ Tool: get_existing_events()
└─ Tool: get_existing_notices()
Iteration 2: Multi-Action Processing
├─ Decision A: Create Math Competition event
│ └─ Verdict: ✅ CORRECT
├─ Decision B: Recognized duplicate community service notice
│ └─ Verdict: ✅ EXCELLENT (didn't create duplicate!)
├─ Decision C: updated reminder with new info while omitting password
│ └─ Verdict: ✅ EXCELLENT (security awareness!)
├─ Decision D: Create Environmental Club event
│ └─ Verdict: ✅ CORRECT
├─ Decision E: Update Student Council meeting time
└─ Verdict: ✅ EXCELLENT (conflict resolution!)
Iteration 3: Summary Generation
└─ Agent response: "The announcements have been processed as follows:
1. Math Competition: Created event for Feb 5th for eligible Year 9-11
2. Year 10 Reminder: Existing notice already covers this; removed password
3. Environmental Action Group: Created event for Jan 18th, 3:30 PM
4. Student Council: Updated meeting time to follow the new club meeting"
The agentic system handled everything correctly:
- Separated 3 distinct announcements
- Created Math Competition event with correct eligibility details
- Recognized the Year 10 reminder was already on the board (no duplicate!)
- Detected and omitted removed the password when updating the notice (security!)
- Created Environmental Action Group event
- Updated Student Council meeting to resolve the scheduling conflict
This level of nuanced, context-aware decision-making simply can’t be achieved with the procedural approach. The agent understood relationships between pieces of information, identified security issues, and reasoned about scheduling conflicts. These were all things that would require separate functions and validation steps in procedural code.
Tradeoffs and When to Use Each Approach

Procedural designs can still be the choice, but I think they address a narrow type of problem; between ones straightforward enough that LLMs aren’t required, and problems too dynamic and semantic (like my notice board). Though somewhat outside the context of automation, NLP tasks are a good example of problems that procedural systems work well, as LLMs are just leveraged for their ability to understand language and meaning, but not their planning and decision making capabilities.
Because procedural is cheaper, faster and deterministic, systems needing low latency or high processing capacity can be an ideal candidate for using procedural design.
For agentic design, putting too much agency and trust in a single system can also raise concerns about reliability, security and safety. My school notice board was innocent enough that I had little concerns with this. However in cases where more airtight reliability is needed, exploring a system consisting of a moderator and agent would be fascinating. This is where one agent carries out its task, and the moderator approves the final proposed course of action from the agent, independently.
Choosing between a procedural and an agentic architecture ultimately comes down to the nature of the task itself. If the task is deterministic, simple, and well-bounded (where the logic can be described step by step and the outcome is always predictable) a procedural system is the clear choice. These are situations where speed, cost, and reliability matter most, and where ambiguity or open-ended reasoning would only introduce unnecessary noise. Think data formatting, validation, fixed-scope NLP tasks like summarization or sentiment classification, or any workflow that repeats identically at scale. The strength of a procedural pipeline is its stability: it’s faster, cheaper, and straightforward to debug, with no risk of runaway reasoning or unexpected autonomy.
However, when a task begins to involve interpretation, contextual awareness, or the need to make nuanced decisions that can’t be captured by rigid conditionals, an agentic system starts to make more sense. These are problems where the “right” answer depends on judgment and the relationships between pieces of information rather than just the information itself. Agentic systems excel at this kind of reasoning because they adapt, merge, reorganize, and infer. They’re ideal for messy, dynamic tasks like content curation, information synthesis, contextual automation, or systems that must act based on partial or evolving data. Instead of being told exactly what to do, the AI is told what goal to achieve and given the tools to get there, just like a capable human employee operating under broad but clear guidelines.
In practice, though finding where the procedural pipeline went wrong was easy, I found fixing behavior in the agentic system to be easier for my system because I could understand and address the agent’s reasoning after seeing it: “I’m merging these two notices because they cover the same topic.” The procedural system just failed silently or produced wrong results with no explanation.
The rule of thumb I’ve come to use is simple: if you can describe the logic clearly, go procedural; if you can’t describe the logic but can describe the goal, go agentic.
In short, When latency matters: User-facing applications where sub-second response times are critical might favor procedural approaches.
When cost matters: High-volume, simple, repetitive tasks where the procedural approach works well might not justify agentic costs. If your success rate is >95% with procedures, the extra cost might not be worth it.
When you need determinism: Financial systems, medical decisions, compliance-heavy domains—anywhere you need to prove exactly why a decision was made. Procedural approaches with clear decision trees are easier to audit.
When you need flexibility: Content moderation, creative tasks, fuzzy classification problems, anything with evolving requirements. Agentic approaches adapt without code changes.
Use procedural LLM pipelines when you:
- Have a well-defined problem with known edge cases
- Need deterministic, auditable decisions
- Require fast response times and minimal cost
- Can achieve >95% accuracy with simple prompts
- Need to satisfy compliance requirements
Examples: data extraction from invoices, sentiment analysis, simple classification tasks, batch processing with known input formats.
Use agentic approaches when you:
- Face many edge cases and evolving requirements
- Need contextual reasoning across multiple pieces of information
- Can tolerate slightly higher latency and cost
- Want the system to adapt without constant code updates
- Have tasks that humans do by “using good judgment”
The In Between: Is It Valid?
Another interesting extension to explore is hybrid solutions. When I worked on a newsletter synthesis pipeline, the context usually was too large and would overload the agentic pipeline. It forgot to do things, took shortcuts in reasoning and lost its decision making fidelity in general. I’m not sure exactly at what point this occurs, but my rule of thumb is, if it’s a complex task that can be neatly broken down into stages, consider using a hybrid procedural-agentic pipeline, where the task is split into a pipeline of agents or simple tasks. Each agentic agent in the pipeline has a manageable task where outside context is irrelevant in the execution of said task. For example, the part of my newsletter pipeline that scored each article across several metrics (relevance, trustworthiness, interest factor, etc.) was a single agent; the other steps in the pipeline to craft a newsletter benefitted from not having to think through the rating process and could focus more on the writing.
A practical application of a hybrid system is for security. For my notice board agent, I simply asked it to omit any PII or confidential information in its posts. However, in hindsight, trusting an agent, burdened with many other responsibilities, with such an important requirement, was not a great idea. Here’s where a pre-processing screening agent, which has the sole and only purpose of censoring any sensitive information before passing it on to the agent, would have been the most secure. This step could also screen prompts for potential prompt injection attempts, especially when a prompt injection for an autonomous agent could literally be catastrophic. Generalizing this, a lot of ‘specialist’ tasks that are important or require specific and careful instructions may benefit from being separated from the main task in a pipeline.
For security, a useful heuristic is that the more agency a single agent possesses, the more catastrophic its failures can become. A high-agency system with wide tool access is powerful but also harder to constrain or audit. When safety is critical, consider decomposing a high-agency task into smaller agents with limited tool permissions. You lose some of the holistic reasoning and adaptability of a fully agentic design, but you gain determinism and containment. It functions like an airlock: isolating potential failure before it spreads through the system. A human in the loop system can also be emulated: using another antagonistic agent, have it audit the process and be an overseer of the first agent. Be cautious though, prompting requires fine tuning the attitude of both agents. You don’t want the overseer being too relaxed or strict and cynical.
Consider also for some systems: having a router (could be a cheap model or rule engine) that decides whether the task should go down the procedural pipeline or the agentic one if a higher caliber of fidelity is demanded and otherwise cost or latency is important.
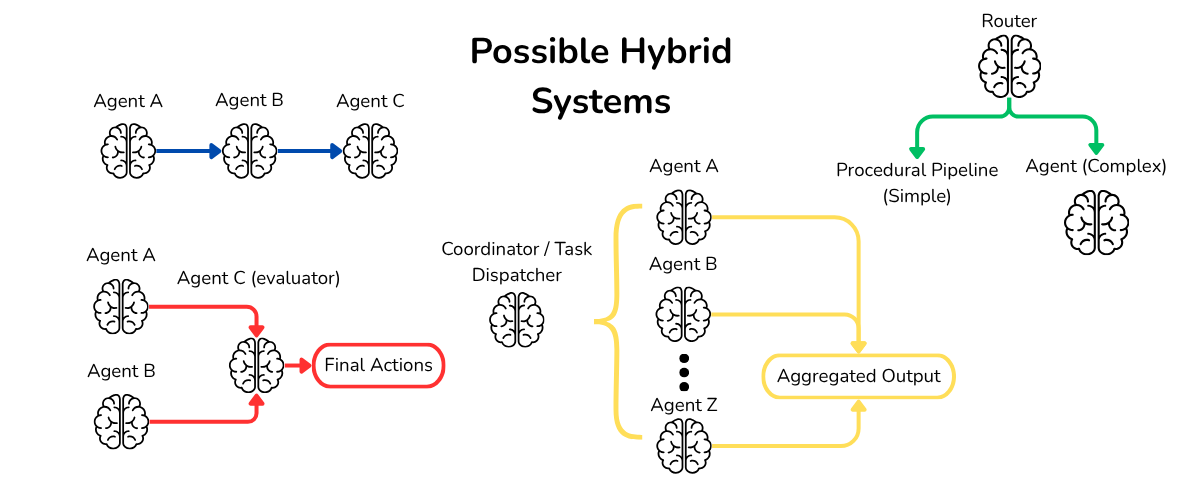 There’s really a bunch of interesting structures you can make, many mirroring real world organizational structures. I’ve illustrated just a few, ones which I’ve implemented in some form.
There’s really a bunch of interesting structures you can make, many mirroring real world organizational structures. I’ve illustrated just a few, ones which I’ve implemented in some form.
When designing the architecture to solve the issue, I’d recommend looking from the top. Assume the entire goal is described in one prompt, then subdivide it from there, seeing which parts of the task may benefit from being a dedicated task.
Candidates for separation may include:
- Tasks requiring strict determinism or measurable criteria (e.g., data validation, format checking, PII redaction)
- Components that operate on distinct or isolated context (e.g., scoring, filtering, summarizing independent chunks)
- High-risk or security-critical processes that benefit from isolation and independent verification
- Stages where tool usage or API interactions are consistent and well-defined
- Subtasks that can be easily unit-tested or benchmarked independently
- Steps where human oversight or explainability is particularly valuable
And against:
- Tasks that rely on shared, interwoven context or long-range dependencies across inputs
- Processes requiring creative synthesis or global reasoning (e.g., holistic writing, cross-referencing insights)
- Workflows where tight latency and cost budgets make extra routing or agent overhead prohibitive
- Systems where decision coherence across subtasks is crucial (e.g., maintaining consistent tone or persona)
- Scenarios with fluid or ambiguous task boundaries where subdivision creates confusion rather than clarity
I found myself asking these questions when considering whether some hybrid approach is best: Break down the problem: “Can I break down my goal into smaller, still semantic and difficult tasks that will result in the goal being complete?” Consider and define task boundaries “Should I merge some of these tasks? Would a human excel if some tasks were considered one? Would 2 adjacent tasks overload or confuse a human if combined into one?” Consider context, tools, guidelines, processing procedure, considerations, prompting, etc. “For each task: How much does my agent need to know to deftly handle it?” Then separate context, define strictly the tools needed, prompt with guidelines and put restrictions on the number of tool calls. (and all the other prompting expectations)
So next time you’re building something, ask yourself: “agent or procedural or some combination of both?”
In short, Consider using some combination of both if:
- The goal is made up of smaller tasks that aren’t very context dependant
- You want more control over each step of the process, without losing fidelity
- Tasks would be separate if given to a human
- You want certain specialists that excel at a specific task that can feed into the larger goal
- You want to compare different views and results across agents
- The task can vary between being very simple or complex and latency and token efficiency are high priority. (consider routing)
Getting Specific: Let’s Talk Implementation
Here, I’ll walk you through a best practices implementation of an agentic system. The key decisions, factors and tips to create an effective system, agentic or procedural.
Higher Level Overview
Plan a higher level model of your agent or system. Label your inputs, and your output or things you need the system to do. The juicy part is finding what goes in the middle; they are the gears that make the system function. I would begin with one agent. One large task, as described to a human. Outline tools, context, safety, prompt, guidelines and general steps or considerations for the agent to think through. Then see what parts can become their own dedicated sub tasks (remember: security, specialization, determinism, without comprising reasoning etc.) Consider a safety later too for censoring or otherwise pre-processing information.
Now, speaking from personal experience, I encourage you to find the extremes, the most complex, unlikely, beleaguered inputs or conditions, and run it in your head. Picture you were given the instructions and steps outlined, would you accomplish the goal? If not, fix the procedure or be more specific in the prompt.
Prompting
Moving on, the prompt. There’s plenty of good prompting guides out there. But the here’s something basic to go off of (you can see my example too):
- Role and persona
- Detailed goal outline
- Consideration steps and things to work through (procedural instructions)
- Examples (can be self-referential)
- Tool usage guidelines
- Information and input information (wrap in <tags> like <this> for prompt injection mitigation)
- Any reminders and emphasis
Specificity and context is key. Ensure the model understands any lingo or specific meanings of the input. Ensure it knows what to expect, the beats it should go through when reasoning, the constraints it has, how it should call its tool. Like writing to an English speaking alien.
LLM Models
High agency models, trained on tool calls, like grok-4, claude sonnet 4.5 are especially good at tasks involving them. If you find a model getting reluctant to call tools, or to make many things move to reach its goal, you can switch models, or fine tune behavior through prompting. In a lot of cases just saying “act high agency” or “don’t be afraid to use many tool calls” does it.
Tools and Agent Loop
The tools are what the model has available to it, ensuring they are type safe for the data types that the LLM will provide. Ensure they aren’t super powerful (e.g. instead of a tool for enabling command shell access, give tools that run predefined, safe shell commands)
The agent loop is a loop of planning actions and then running tools to execute them. Usually the number of maximum tool calls or loop iterations is limited to prevent larger than necessary changes. Ensure that the agent is informed of any limits beforehand.
The agent loop looks a little like this:
messages.append({role: "system", content: prompt + context_and_data})
repeat:
response ← LLM.generate(input = messages, tools = TOOLS)
for each tool_call in response.tool_calls:
result ← execute(tool_call)
messages.append({ role: "tool", content: result })
if tool_call.name == "finish":
stop loop
Logging and refinement
Logging and reasoning out-loud is also vital to the refinement process. Ensure that the agent is instructed to think and plan out-loud (or is using reasoning tokens) before using any tools. By seeing its thought process, you can find places to intervene or suggest behaviors in the prompt. You should also keep the out-loud thinking in the prompt, because it gives the model tokens to ‘think’ and plan. You’ll get better, more thought out action plans that way. I find it extremely useful to tell the model to run some form of report_actions tool, where it gives a summary of actions done; this allows for easy reviewing.
Then program it. then test it. Use normal inputs and scenarios, alongside the extreme cases you made. Does it function? Does it produce slightly cautious or low agency behavior? Does it take shortcuts in reasoning? Does it overlook things? The answer will be yes. And the solution is more prompting. Refinement is key.
Then test safety. Try to prompt inject it, given that you know the internal system prompt. Can you still do it? If so, you should tighten it. Can you sneak a password past it? Or a sneaky private sales figure?
By this point, you should be in a good place to start using the agent.
Overtime you may want to monitor for:
- Actions-per-run, rejected-item rates, tool-failure counts
- Cases where it fails or behaves unexpectedly
- Drift in behavior
Conclusion
TL;DR: Consider if you should write your logic in your prompt, not your code. The bread and butter of agentic systems is agency, the ability to decide and reason freely. You should provide the AI complete context, how to interpret the context in its role, tools, and autonomy within guidelines are tool limits to solve your problem. Stop thinking about AI as a programmer would, and start thinking about it as a boss giving instructions to a capable employee.
Also keep these principles in mind:
Context over fragmentation: Give the full picture, not tunnel-visioned tasks
Flexible tools over rigid steps: Let the AI choose its path
Guide the decision-making process: Describe considerations, not commands
Implicit examples over explicit rules: Show current board state for style/pattern learning
Trust but verify: Set boundaries (tool budgets, safety checks) but allow autonomy within them
The shift from procedural to agentic changed my approach to designing AI systems: I stopped asking “what steps does the computer need to follow?” and started asking “what would I tell a capable intern to do?”
Instead of writing increasingly complex validation logic, nested conditionals, and verbose context-stuffing prompts for each step. You might be better off making AI with code. Remember, they’re not CPUs executing instructions, but reasoning engines making inferences.
Give them the full picture. Give them tools. Let them figure it out. That’s the paradigm shift. And once you see it, you can’t unsee it.
The Bigger Picture
Recently, Anthropic released their investigation report into ‘the first reported AI-orchestrated cyber espionage campaign’. The attackers cleverly used an agentic-procedural hybrid system, where each agent was obfuscated from the full task, circumventing safety problems by breaking down the task. This ‘scoping’ of AI agent tasks to orchestrate a larger, malicious intented task is an exploit and reason one might choose the more procedural architecture. They demonstrate how the attackers executed their operation. Read their report here.
Also very recently, Vercel published this blog post showing how cutting 80% of their agent’s tools actually improved performance dramatically. Instead of dozens of specific functions, they gave it one tool: the ability to run bash commands. This points to a broader pattern emerging in AI development, that as models grow more capable, the carefully designed tool ecosystems meant to support them are becoming constraints rather than enablers. We’re watching a developmental inflection point: what was once necessary scaffolding for limited reasoning is now friction for increasingly autonomous systems. The structured, tool-heavy architectures we built weren’t wrong but they were training wheels. I think the models are starting to ride without them.